Open Network Laboratory
A Resource for Networking Researchers and Educators
When citing ONL, please use the following Citation:
A Remotely Accessible Network Processor-Based Router for Network Experimentation, by Charlie Wiseman, Jonathan Turner, Michela Becchi, Patrick Crowley, John DeHart, Mart Haitjema, Shakir James, Fred Kuhns, Jing Lu, Jyoti Parwatikar, Ritun Patney, Michael Wilson, Ken Wong and David Zar. In ''Proceedings of ANCS'', 11/2008.
The Open Network Laboratory is a resource for the networking research and
educational
communities, designed to enable experimental evaluation of advanced networking
concepts in a realistic working environment.
The National Science Foundation has supported ONL through grants
CNS 0230826, CNS 05551651 and MRI 12-29553.
The laboratory is built around open-source,
extensible, high performance routers that have been developed at
Washington University, and which can be accessed by remote
users through a Remote Laboratory Interface (RLI).
The RLI allows users to configure the testbed network,
run applications and monitor those running applications using the
built-in data gathering mechanisms that the routers provide.
The RLI provides support for data visualization and real-time remote
displays, allowing users to develop the insights needed to
understand the behavior of new capabilities within a complex
operating environment.
The routers that support the testbed are Software Routers (SWRs) hosted on standard Dell servers
running the Ubuntu operating system. They come in a variety of
configurations.
This technology enables
systems researchers to evaluate
and refine their ideas, and then to demonstrate them to those
interested in moving the technology into new products and services.
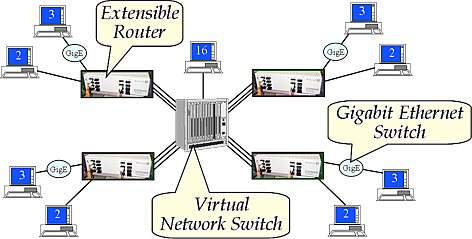 The organization of the ONL is shown to the right. (figure needs updating)
The facility has 24 SWRs which come in a variety of configurations.
(for example: 5 1G interfaces, 2 10G interfaces, 16 1G interfaces or 8 1G interfaces).
These routers can be linked together in a variety
of network topologies, using a central Virtual Network Switch (VNS),
which serves as an electronic patch panel.
The facility also
includes over 100 rackmount computers, which serve as end systems.
All of the end systems and SWR ports are connected to the VNS.
ONL also includes multi-core servers which support Virtual Machines (VMs) for
end user use.
The organization of the ONL is shown to the right. (figure needs updating)
The facility has 24 SWRs which come in a variety of configurations.
(for example: 5 1G interfaces, 2 10G interfaces, 16 1G interfaces or 8 1G interfaces).
These routers can be linked together in a variety
of network topologies, using a central Virtual Network Switch (VNS),
which serves as an electronic patch panel.
The facility also
includes over 100 rackmount computers, which serve as end systems.
All of the end systems and SWR ports are connected to the VNS.
ONL also includes multi-core servers which support Virtual Machines (VMs) for
end user use.
The figure below shows the user interface. (figure needs updating)
New configurations can be built by instantiating routers and
hosts and connecting them together graphically.
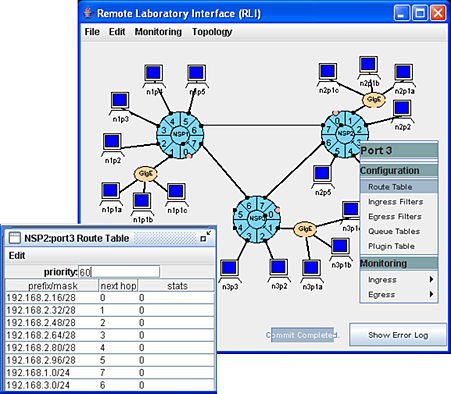 Routing tables can configured through pull-down menus
accessed by clicking on router ports.
Packet filters and custom software plugins can
be specified in much the same way.
Once a configuration has been created, it can be saved to a file
for later use. When a user is conducting an experiment, the
configuration is submitted to the ONL management server,
which generates the low level control messages to configure
the various system components to realize the specified
configuration.
Routing tables can configured through pull-down menus
accessed by clicking on router ports.
Packet filters and custom software plugins can
be specified in much the same way.
Once a configuration has been created, it can be saved to a file
for later use. When a user is conducting an experiment, the
configuration is submitted to the ONL management server,
which generates the low level control messages to configure
the various system components to realize the specified
configuration.
The graphical interface also serves as a control mechanism,
allowing access to various hardware and software control variables
and traffic counters.
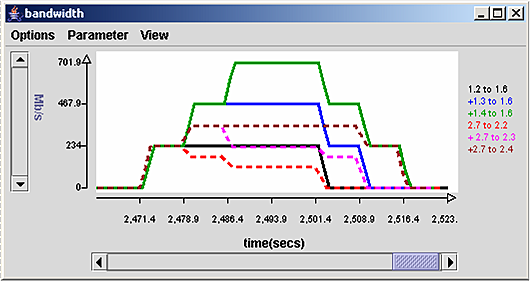 The counters can be used to generate
charts of traffic rates, or queue lengths as a function of time,
to allow users to observe what happens at various points in the
network during during their experiment and to allow them to
document the results of the experiment for presentation
and publication.
An example of such a chart is shown to the right.
The counters can be used to generate
charts of traffic rates, or queue lengths as a function of time,
to allow users to observe what happens at various points in the
network during during their experiment and to allow them to
document the results of the experiment for presentation
and publication.
An example of such a chart is shown to the right.
Supported by:
National Science Foundation
under grants CNS 0230826, CNS 05551651 and MRI 12-29553.
Disclaimer:
Any opinions, findings and conclusions or recomendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation (NSF).